Multi-agent is Phrony’s model for composing specialized agents into one coordinated execution. Instead of one monolithic agent, you split work: a parent orchestrates, and sub-agents handle focused parts with their own model, instructions, and integration tools. The whole tree—root run and every child run—lives in a single session. The session is the top-level, user-facing unit of work: history, status, and limits roll up from the root, while the trace shows how parent and child runs interleave.Documentation Index
Fetch the complete documentation index at: https://docs.phrony.com/llms.txt
Use this file to discover all available pages before exploring further.
Sub-agent execution mode
Agents in Sub-agent execution mode are the building blocks of multi-agent. They are not standalone entry points.| Triggerable by Scheduled or API triggers? | No — you do not start them with triggers or the embedded API. |
| Callable by a parent? | Yes — when a parent version allowlists them, they appear as tools the parent model can call. |
| Own configuration? | Yes — full version config: model, instructions, operations, limits, anomaly control, and so on. |
| Agent in the loop (AITL)? | Yes — always, as below. Sub-agents talk up to the parent, not to end users, when they need help mid-run. That behavior is part of the platform; you do not turn it on or off. |
Parent configuration
On a parent agent’s version (not Sub-agent mode), the Multi-agent block—when your workspace plan supports it—controls delegation. The same area is documented on the agent page; here is the behavioral summary.| Field | What it does |
|---|---|
| Can execute sub-agents | If off, this version never dispatches child agents, regardless of the allowlist. |
| Allowed sub-agents | Which Sub-agent–mode agents this version may call. The model only sees and may invoke agents listed here; there is no open discovery. |
| Sub-agent execution model | Sequential or Parallel (see below). Shapes how multiple sub-agent invocations are run once the model requests them. |
Sub-agent execution models
Sequential — After a sub-agent call, the parent waits for that child run to finish before it may issue the next sub-agent call. Results from one call are available before the next starts. Parallel — The parent may request multiple sub-agent invocations in one batch; the platform runs the corresponding child runs in parallel and the parent only continues after all of them in that batch complete, with their results available together.Sequential vs parallel do not decide whether a sub-agent runs. They define how ordered vs batched execution is when the model asks for more than one dispatch in a compatible way.
Run tree
Each sub-agent dispatch creates a child run. All runs in the tree share the same session. The initial trigger (for example a schedule, API, or event trigger) still roots at the parent run at depth 0.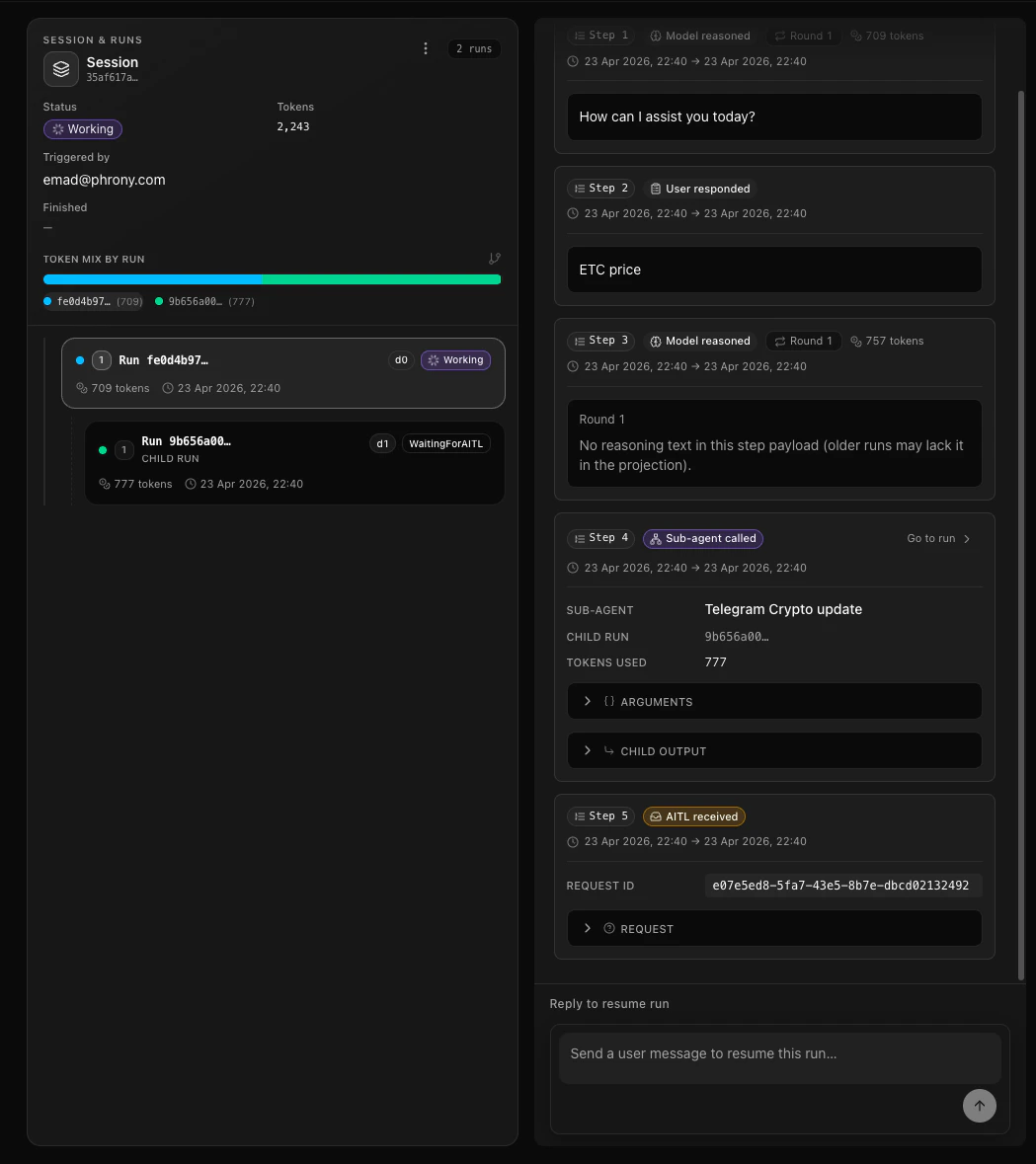
Step types in the trace
Multi-agent runs add step kinds you will see in the session timeline (names may vary slightly in the product UI):| Step (concept) | Where | Meaning |
|---|---|---|
| Sub-agent call | Parent | The parent started a sub-agent; records which agent, the input, the child run id, and (for parallel) a group id. |
| Sub-agent result | Parent | The child run finished; the parent’s trace records the result and how long the child took. |
| AITL request | Child | The sub-agent paused and asked the parent a question. |
| AITL response | Child | The parent’s answer was applied; the sub-agent can continue. |
| AITL received | Parent | The parent’s model saw a question from a child. |
| AITL resolved | Parent | The parent answered (or escalated); the child can proceed. |
AITL (agent in the loop)
Agent in the loop (AITL) is the dedicated guide: how escalation to people works, how AITL differs from HITL, and what the parent and sub-agent each must do. The following fits AITL into the multi-agent picture (same session, run tree, and steps). AITL is how a sub-agent can pause and get input from its parent—the analogue of a human in the loop for root agents, but agent-to-agent: the parent’s model (and, if needed, a human in HITL mode) supplies the answer.- Sub-agents do not talk to your end users directly; they only communicate with the parent. If a human is needed, the root execution mode and user tasks path applies from the parent’s side of the house.
- The parent may answer from its own context or escalate so a person answers via a user task, depending on mode and what the product allows in that session.
- Request- and HITL- mode parents can both handle AITL from children; AITL is about in-tree agent coordination, not the same as external human gating (which mode still governs for the root agent).
Safety
Cycle detection — Before a sub-agent call, Phrony checks the chain of ancestors. If the target would create a loop (an agent re-entering a chain it already lives in), the call is rejected and the current run does not proceed with that dispatch. Maximum depth — A platform limit caps how deep the tree can go (default 5 levels below the root: depth 0 is the parent run, each nested sub-agent call adds one). At the limit, a run cannot start another sub-agent. Access control — The parent model can only call sub-agents that appear in the allowed list on its version. Anything not allowlisted is invisible as a sub-agent tool. Limits — Per-run caps (for example max iterations, tokens, tool calls) still apply per run on each version. The root version can also set session-level token and duration limits that apply across the whole session (parent + all nested runs). Hitting any enforced limit ends execution according to the product rules; session caps and per-run caps are independent checks.Runtime guidance (what Phrony adds to instructions)
Phrony may append extra instructions after your version system text so that parent and sub-agent handoffs stay reliable, even if your own prompts are short. Your instructions always come first; the platform addendum comes second.When it applies
- Sub-agent runs: additional rules always apply, because every sub-agent invocation is expected to follow the same coordination pattern.
- Parent runs (root or a nested “orchestrator” that can also delegate): additional rules apply only when that version can execute sub-agents and has at least one allowed, reachable sub-agent. Versions with delegation turned off, or with an empty allowlist, do not get the parent addendum.
- Structured output — If your version defines an output JSON schema and the run uses tools, Phrony may add a reminder that the final answer (when the model is done with tools) must be raw JSON matching that schema, without extra markup.
Sub-agent rules (behavior)
- If input is missing or ambiguous, the model must ask the parent through the AITL path instead of pretending the task is done with a clarifying final answer in plain text.
- If the sub-agent’s version has integration (operation) tools configured, the model is expected to accomplish the task using those tools when that is what the work requires. Finishing with a final structured answer without using any of those operation tools, when the run was supposed to use them, is treated as a violation and the run can fail at completion time. Asking a parent for clarification, or other non-operation tools, do not substitute for the operation work the version was set up to perform.
- If there are no operation tools, the model should only finish when it can answer from what it has, or else ask the parent.
Parent rules (behavior)
- When a sub-agent’s result still includes a pending question to the parent (agent-in-the-loop), the parent model must resolve that on the next turn using the AITL tools (answer itself or escalate to a person where that tool exists) — not with unrelated tools first, and not with plain text that bypasses the AITL tools. Skipping that leaves the child stuck; Phrony may fail the parent run in those cases.
- In HITL-mode root parents, a separate line in the addendum can remind the model: mid-task input that originated from a sub-agent should go through escalation to the user when a human is required, not only a free-text pause to the operator, so answers wire back to the right child. Nested parents that are themselves sub-agents but can delegate further use the same parent contract with stricter rules around human escalation, because a sub-agent is not a full HITL root session.
Models, schemas, and production readiness
Prefer newer, more capable models for multi-agent work. Orchestration, sub-agent tool choice, structured handoffs, and AITL all punish weak models. Latest-generation, higher-capability SKUs are usually a better default than older or much smaller models—especially for parent agents—unless you have validated a lighter model end to end.
Model choice: parent vs sub-agents
- Parent agents reason about when to delegate, interpret child results, and resolve AITL. Give them a more powerful model than you would pick for a trivial single-step task.
- Sub-agents can sometimes use smaller models when the task is narrow and contracts are strict—but they still must honor tools, schemas, and AITL rules. If a child model frequently skips operations or returns ambiguous output, stepping up model class is often cheaper than prompt padding.
Input and output schemas
Define both input and output JSON Schema on each version in the tree—root and every sub-agent you allowlist. Consistent contracts reduce surprises: the parent and runtime see predictable shapes, malformed API or trigger payloads fail early, and downstream systems can rely on typed results. Ad hoc or undocumented fields across agents make failures harder to trace in production. Use the schema builder to make the contract between agents explicit. A good contract says exactly what the parent must provide, what the sub-agent is allowed to assume, and what the child must return. Prefer precise field names, required properties for values the child cannot work without, enums for constrained choices, and short descriptions that explain business meaning—not only data type. Pair those schemas with clear, narrow instructions on both sides of the handoff. The parent should know when to delegate, which context to include, and how to consume the result. The sub-agent should know its goal, boundaries, tools, escalation conditions, and output obligations. In practice, well-defined input/output schemas plus precise instructions are one of the biggest levers for a reliable multi-agent system: they reduce ambiguous handoffs, make AITL questions more targeted, and keep child results easier for the parent to use.Temperature, top-p, and top-k
There is no one-size-fits-all; tune temperature, top-p, and top-k with your own evals. Useful defaults to start from:- Parents and orchestration: favor lower temperature for steadier routing, fewer protocol deviations, and more reliable AITL handling. Raise it only when you explicitly want more variety in phrasing or exploration.
- Strong structured outputs: keep sampling relatively conservative so completions stay close to your schema.
- Top-p and top-k: behavior varies by provider and model—see Model & Prompt. When unsure, leave top-p and top-k empty in the dashboard so the provider’s defaults apply, then adjust after you measure.
Validate before production
Swapping models or vendors can change tool-use habits, JSON shape, and escalation behavior even when prompts stay the same. Exercise representative runs, compare candidates if you change SKUs, and iterate prompts and sampling until the system is stable. Treat a model change like any other production configuration: verify it before you ship, not only in the dashboard test pane.Prompts, platform behavior, and getting help
If a multi-agent run behaves unexpectedly, treat prompt and contract quality as the first lever: clearer goals, explicit delegation boundaries, and tighter input/output schemas usually fix more than a small sampling tweak. Models still interpret your instructions; weak or ambiguous prompts show up as wrong tool use, vague handoffs, or malformed structured output.Phrony’s multi-agent implementation is tested against complex scenarios and configurations, and we regularly validate it with hundreds of automated test cases so the system stays stable and consistent as we ship. When we find a bug in the platform, we communicate the cause and the fix you should expect.That does not mean every surprising trace is a Phrony defect. Most odd behavior traces back to the LLM (non-compliance, drift between settings) or to configuration—not to the runtime mis-routing your session. Improve your prompts and version settings before assuming the product is at fault.If you believe you have hit a genuine edge case in Phrony, open Get help in the Phrony dashboard and reach us through the official support channels listed there.
Session completion
- A session is only considered completed in the end-user sense when the root run finishes successfully. Child run completions by themselves do not end the session while the parent is still working or waiting to resolve AITL.
- Session-level failure is generally driven by the root run’s outcome. A child run can fail; the parent sees that in the sub-agent result and can react. A child failure does not automatically end the parent session in every case—behavior depends on how the parent’s model and configuration proceed.